 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting for Mathematical Lineation in Jim Crace's "Quarantine" and T. S. Eliot's "Four Quartets"
Sep 20, 2001
The mathematical distinction between prose and verse may be detected in writings that are not apparently lineated, for example in T. S. Eliot's "Burnt Norton", and Jim Crace's "Quarantine". In this paper we offer comments on appropriate statistical methods for such work, and also on the nature of formal innovation in these two texts. Additional remarks are made on the roots of lineation as a metrical form, and on the prose-verse continuum.
Isometric Lineation in English Texts: An Empirical and Mathematical Examination of its Character and Consequences
Aug 14, 1998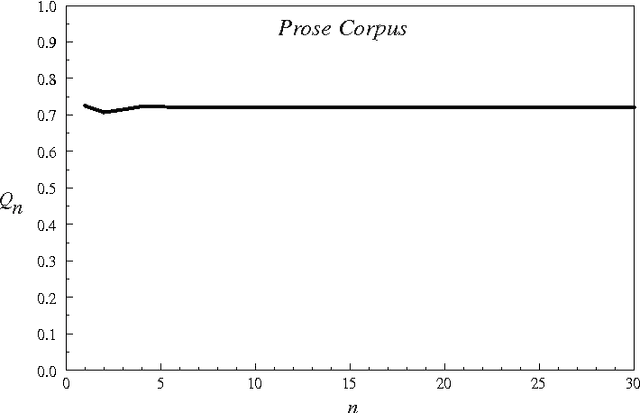
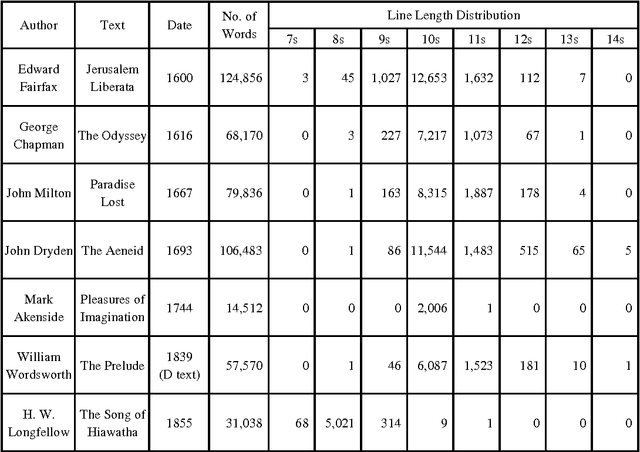
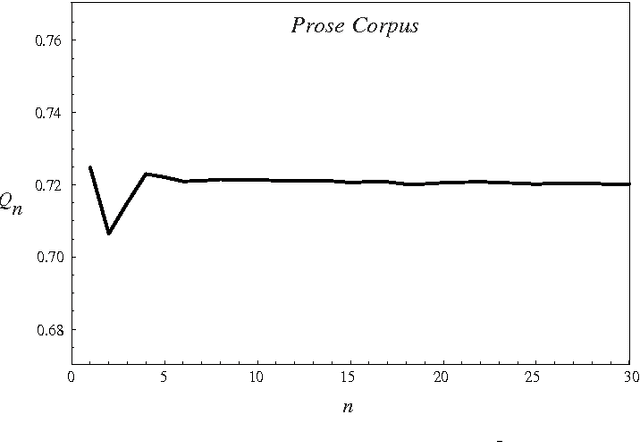
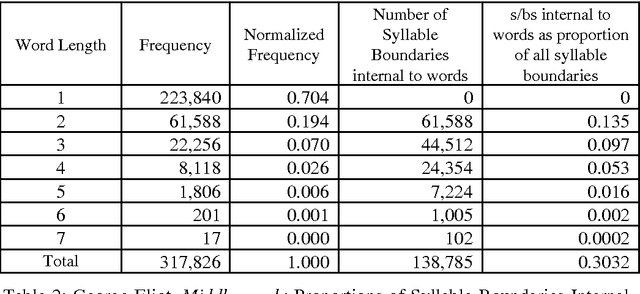
In this paper we build on earlier observations and theory regarding word length frequency and sequential distribution to develop a mathematical characterization of some of the language features distinguishing isometrically lineated text from unlineated text, in other words the features distinguishing isometrical verse from prose. It is shown that the frequency of syllables making complete words produces a flat distribution for prose, while that for verse exhibits peaks at the line length position and subsequent multiples of that position. Data from several verse authors is presented, including a detailed mathematical analysis of the dynamics underlying peak creation, and comments are offered on the processes by which authors construct lines. We note that the word-length sequence of prose is random, whereas lineation necessitates non-random word-length sequencing, and that this has the probable consequence of introducing a degree of randomness into the otherwise highly ordered grammatical sequence. In addition we observe that this effect can be ameliorated by a reduction in the mean word length of the text (confirming earlier observations that verse tends to use shorter words) and the use of lines varying from the core isometrical set. The frequency of variant lines is shown to be coincident with the frequency of polysyllables, suggesting that the use of variant lines is motivated by polysyllabic word placement. The restrictive effects of different line lengths, the relationship between metrical restriction and poetic effect, and the general character of metrical rules are also discussed.
Word Length Frequency and Distribution in English: Observations, Theory, and Implications for the Construction of Verse Lines
Aug 13, 1998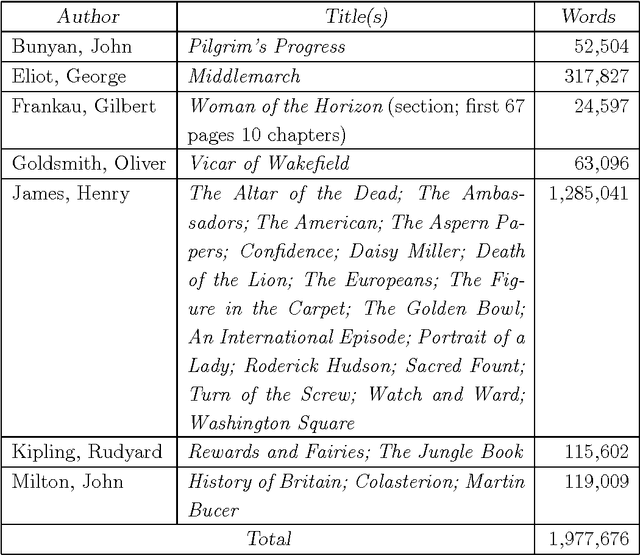
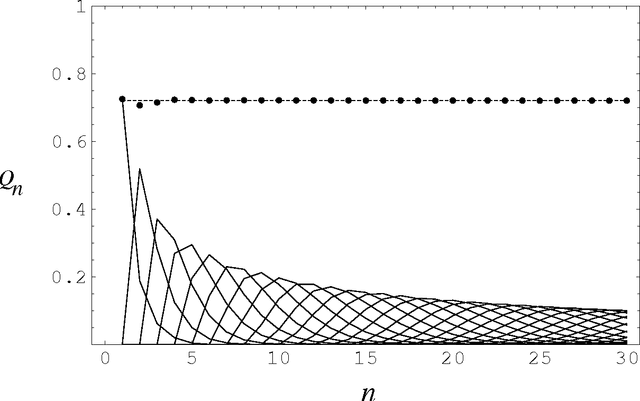
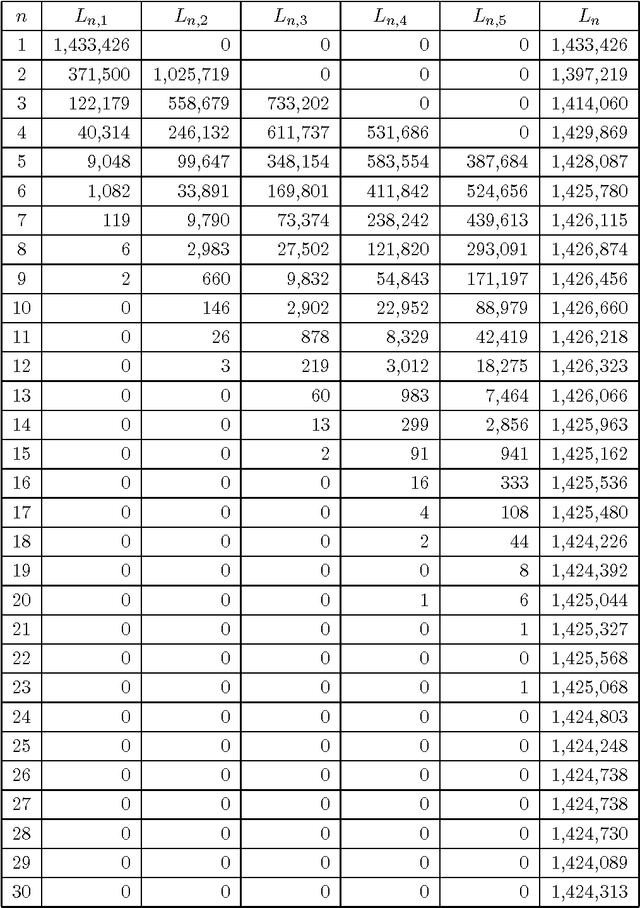
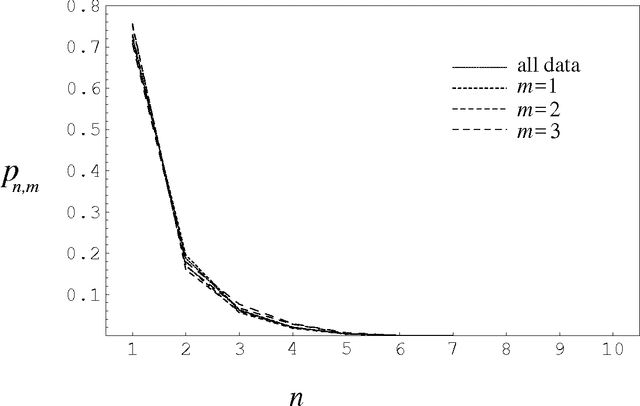
Recent observations in the theory of verse and empirical metrics have suggested that constructing a verse line involves a pattern-matching search through a source text, and that the number of found elements (complete words totaling a specified number of syllables) is given by dividing the total number of words by the mean number of syllables per word in the source text. This paper makes this latter point explicit mathematically, and in the course of this demonstration shows that the word length frequency totals in English output are distributed geometrically (previous researchers reported an adjusted Poisson distribution), and that the sequential distribution is random at the global level, with significant non-randomness in the fine structure. Data from a corpus of just under two million words, and a syllable-count lexicon of 71,000 word-forms is reported. The pattern-matching theory is shown to be internally coherent, and it is observed that some of the analytic techniques described here form a satisfactory test for regular (isometric) lineation in a text.